La gestion des incidents en ITSM : réagir vite et bien
Et si la gestion des incidents devenait un levier de résilience ?

Formé à Centrale et certifié ITIL, Abdou Razak travaille sur des missions de structuration SI et d’optimisation des processus ITSM

1. Introduction
1.1. Contexte historique et tendance actuelle autour de l’ITSM
L’ITSM (Information Technology Service Management), né dans les années 1980, a évolué pour passer d'un support technique réactif à une approche stratégique et proactive. Initialement, les départements IT se contentaient de résoudre des problèmes techniques ponctuels. Aujourd'hui, face à la complexité croissante des systèmes et à l'omniprésence des services digitaux, l’ITSM vise à aligner les services IT sur les objectifs globaux de l’entreprise, intégrant des référentiels comme ITIL pour uniformiser les bonnes pratiques.
Dans un contexte où les interruptions de services peuvent avoir des impacts financiers, sécuritaires et sur l’image, l'ITSM devient un levier clé pour assurer la résilience des organisations. En 2024, des technologies telles que l’automatisation, le cloud et l’intelligence artificielle redéfinissent cette discipline, en permettant une gestion plus prédictive et proactive des incidents.
La gestion des incidents, qui était autrefois une réponse réactive à des interruptions de service, se transforme aujourd’hui en un processus agile et proactif. L’objectif n’est plus seulement de résoudre rapidement les incidents, mais aussi de les prévenir et d’en réduire leur fréquence et leur impact. L’automatisation et l’analytique avancées, combinées à l’intelligence artificielle, permettent de détecter des anomalies avant qu'elles ne se transforment en incidents, accélérant ainsi leur résolution et améliorant l’expérience utilisateur.
1.2. Définition de la gestion des incidents
La gestion des incidents est un processus clé de l’ITSM (Information Technology Service Management) qui vise à restaurer le fonctionnement normal des services informatiques aussi rapidement que possible après une interruption, afin de minimiser les impacts sur les activités de l’organisation. Un "incident" se réfère à toute interruption ou dégradation imprévue d’un service IT ou d’un composant susceptible d’affecter les utilisateurs ou l’entreprise.
Ce processus implique plusieurs étapes, du signalement initial à la résolution finale, en passant par l’escalade vers des niveaux de support plus spécialisés si nécessaire. Une gestion des incidents efficace assure non seulement la continuité des opérations mais réduit aussi le stress opérationnel sur les équipes IT.
Aujourd’hui, avec l’adoption des technologies avancées telles que l’automatisation et l’intelligence artificielle, la gestion des incidents tend vers une approche proactive et prédictive, permettant une détection précoce et une résolution automatisée de nombreux incidents avant qu’ils n’impactent les utilisateurs.
1.3. Importance de la gestion des incidents pour les entreprises/organisation et les DSI
Pour les entreprises, une gestion des incidents structurée est essentielle afin d’éviter des interruptions prolongées qui impactent non seulement la productivité mais aussi la crédibilité.
Avec la dépendance croissante aux services digitaux, les incidents peuvent provoquer des impacts financiers immédiats et des conséquences plus larges, telles qu'une diminution de la satisfaction et de la fidélité des clients. Une panne prolongée sur des outils critiques (ERP, CRM, plateforme e-commerce) peut entraîner des pertes de revenus directes, des amendes pour non-respect de certaines obligations de service, et une perception négative de la marque.Par exemple, dans le secteur du e-commerce, une panne pendant une période de pointe (comme le Black Friday) peut se traduire par des millions en pertes de chiffre d’affaires.
Pour la DSI, la gestion des incidents représente donc un levier stratégique.Elle permet de maintenir la stabilité des services tout en minimisant les coûts associés aux interventions d’urgence.
Une DSI efficace, capable de répondre rapidement aux incidents, renforce sa crédibilité en interne et limite les interruptions dans les opérations de l'entreprise.En outre, une approche proactive de la gestion des incidents aide la DSI à se concentrer davantage sur les initiatives stratégiques, en évitant que les équipes techniques ne soient submergées par des résolutions de problèmes récurrents. En utilisant des outils de surveillance avancés (supervision, observabilité) et l’automatisation, la DSI peut réduire le nombre d’incidents qui atteignent les utilisateurs finaux et améliorer la qualité du service.
1.4 Objectifs de la gestion des incidents
Les principaux objectifs de la gestion des incidents incluent :
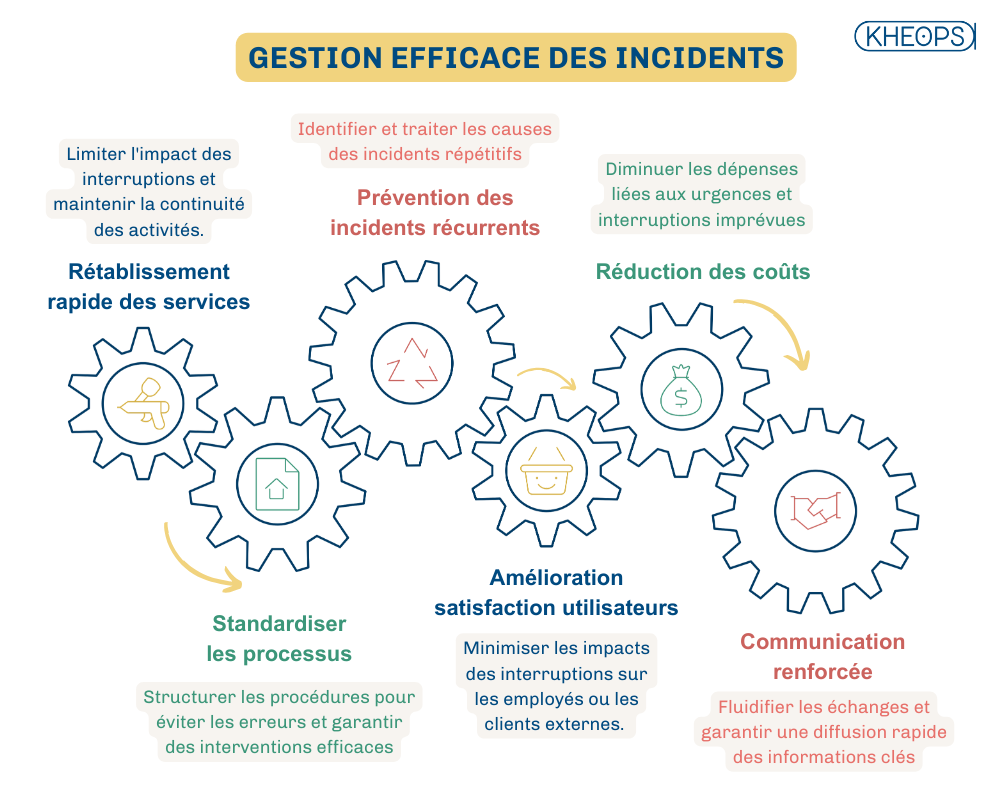
2. Fondamentaux de la gestion des incidents
2.1. Concepts clés : différence entre incident, problème, demande de service
Dans le cadre de la gestion des services informatiques, il est essentiel de comprendre la différence entre un incident, un problème et une demande de service. Ces trois concepts sont souvent confondus, mais chacun correspond à un type d’intervention distinct avec des processus spécifiques.La gestion des incidents vise principalement à rétablir un service, tandis que la gestion des problèmes se concentre sur l’identification et l’élimination des causes sous-jacentes de plusieurs incidents. La gestion des demandes, quant à elle, se rapporte à la fourniture de services prévus et récurrents.
%252520(2).png)
2.2 Typologies d'incidents
Un incident dans le contexte d'ITIL est caractérisé par les éléments suivants :
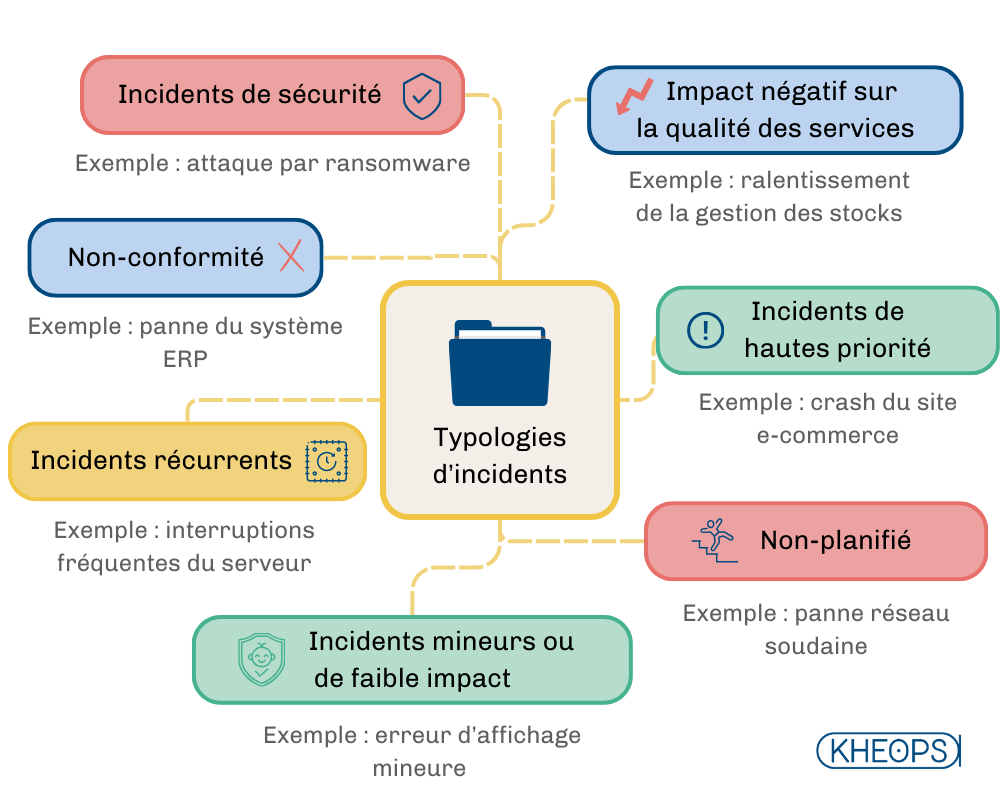
2.3 Impact des incidents sur les utilisateurs et l'organisation
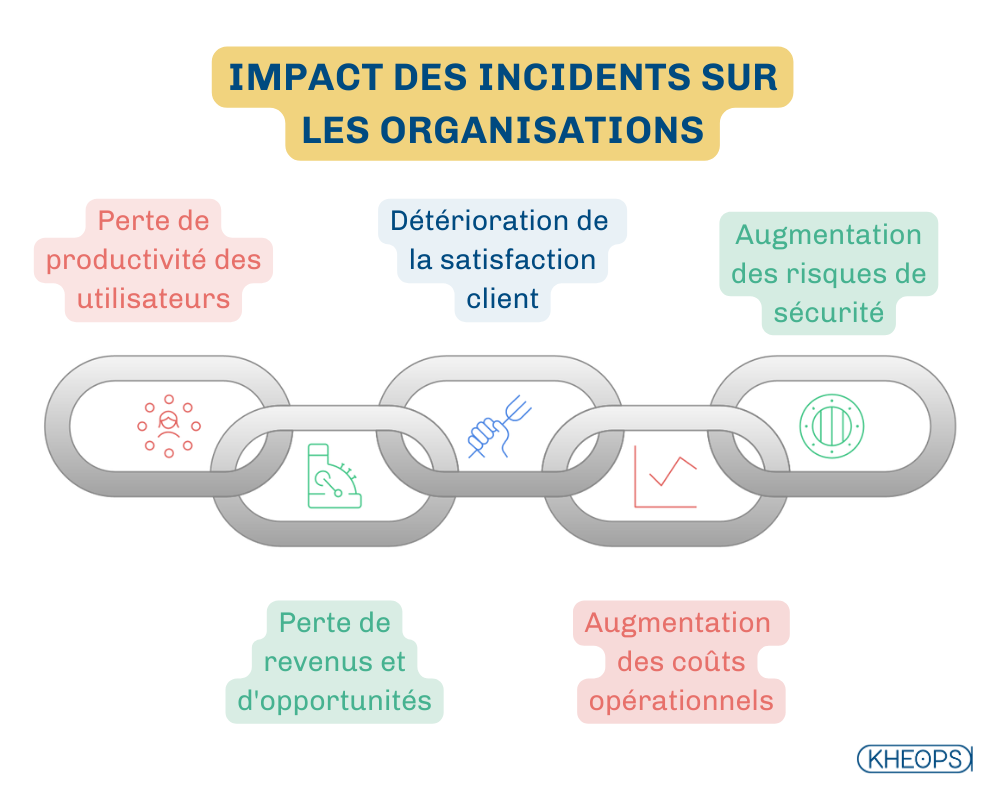
Les incidents ont des répercussions variées sur les utilisateurs finaux et sur l'organisation dans son ensemble. Une gestion efficace des incidents permet de réduire ces impacts, mais il est crucial de bien comprendre leurs différentes manifestations pour anticiper et limiter les conséquences.
Perte de productivité des utilisateurs :
- Les interruptions de service empêchent les utilisateurs d’accomplir leurs tâches, ralentissant les opérations et augmentant le temps de traitement des activités. Pour une organisation, cela se traduit par une baisse de la productivité globale et un temps de travail supplémentaire pour rattraper les retards. Par exemple, si un ERP est indisponible, les employés ne peuvent pas accéder aux informations critiques pour leurs activités, ce qui engendre des pertes de temps significatives.
Perte de revenus et d’opportunités commerciales :
- Les incidents touchant les systèmes clients, comme les plateformes e-commerce, peuvent générer des pertes de chiffre d’affaires immédiates et des opportunités manquées. Une interruption pendant une période stratégique de vente, telle que les promotions saisonnières, réduit les ventes et nuit à la rentabilité. De plus, les clients mécontents risquent de se tourner vers des concurrents, impactant ainsi la part de marché de l’entreprise.
Détérioration de la satisfaction client et de l’image de marque :
- Les incidents répétitifs ou les interruptions de longue durée compromettent la qualité de l’expérience client, surtout pour les services orientés clients (sites web, applications). Les utilisateurs insatisfaits peuvent perdre confiance en l'entreprise et choisir des alternatives, ce qui dégrade la réputation de la marque et nuit à la fidélité des clients. Dans un marché compétitif, cela peut avoir des effets à long terme sur la position de l’entreprise.
Augmentation des coûts opérationnels :
- La gestion des incidents requiert des ressources immédiates, mobilisant des équipes IT pour rétablir les services rapidement. Cela engendre des coûts supplémentaires liés aux interventions d’urgence, à l’achat d’outils spécialisés, ou au remplacement de composants défectueux. Les incidents récurrents accentuent ces coûts, en absorbant une partie significative du budget IT qui pourrait être allouée à des projets stratégiques.
Risque de sécurité accru :
- Certains incidents, notamment ceux impliquant des failles de sécurité, exposent l’entreprise à des cyberattaques ou des pertes de données sensibles, compromettant la sécurité de l’organisation. Ces incidents peuvent entraîner des coûts élevés pour corriger les vulnérabilités et restaurer les systèmes, en plus des risques juridiques ou financiers si des réglementations (comme le RGPD) sont enfreintes. Un incident de sécurité grave peut également nuire à la réputation de l’organisation.
2.4 Bonnes pratiques et normes autour de la gestion des incidents (ITIL, ISO/IEC 20000)
Pour une gestion des incidents efficace, des normes et frameworks comme ITIL et ISO/IEC 20000 offrent des directives essentielles.Ces référentiels ont été conçus pour structurer la gestion des services IT, incluant des processus spécifiques pour la gestion des incidents. ITIL recommande des processus standardisés pour réduire les variations dans le traitement des incidents et optimiser la gestion du temps.
Voici une synthèse des meilleures pratiques :
.png)
- ITIL recommande des processus standardisés pour réduire les variations dans le traitement des incidents et optimiser la gestion du temps.
- ISO/IEC 20000 offre un cadre de gouvernance qui encourage les organisations à aligner leurs pratiques IT sur des normes de qualité reconnues.
- Pratiques additionnelles soutiennent l’optimisation des opérations IT en favorisant une détection précoce des anomalies, des engagements de résolution clairs et un renforcement des compétences pour une gestion plus réactive et efficace.
Ces bonnes pratiques aident à structurer la gestion des incidents, garantissant une meilleure continuité de service et satisfaction utilisateur.
3. Acteurs et rôles dans la gestion des incidents
3.1 Rôles et responsabilités
La gestion des incidents mobilise différents acteurs, chacun ayant des responsabilités spécifiques pour assurer la continuité des services et minimiser l’impact des interruptions.
- Propriétaire du processus : Chargé de définir la stratégie globale de gestion des incidents, il s’assure que le processus est aligné avec les objectifs stratégiques de l’entreprise. Il veille à la conformité avec les bonnes pratiques ITSM, au suivi des indicateurs de performance, et à l'amélioration continue des processus.
- Gestionnaire d’incidents : Responsable opérationnel du processus, il coordonne les actions des équipes pour une résolution rapide des incidents. Cela comprend l’identification et la priorisation des incidents, la mobilisation des ressources nécessaires, et le suivi des incidents jusqu’à leur clôture. Il est également chargé de produire des rapports post-incident pour analyser les causes et recommander des améliorations.
- Équipes de support : Elles sont souvent structurées en plusieurs niveaux, chacun traitant les incidents selon leur complexité :
- Support niveau 1 : Il s’agit de la première ligne d’intervention. Cette équipe enregistre les incidents signalés, fournit des solutions de base, et résout les incidents les plus simples. Si un incident dépasse leurs compétences, il est escaladé au niveau 2.
- Support niveau 2 : Cette équipe gère les incidents plus complexes qui nécessitent une expertise technique approfondie. Elle mène des analyses plus poussées et travaille à résoudre les incidents escaladés par le support niveau 1.
- Support niveau 3 : Ce niveau regroupe des experts techniques ou des spécialistes du fournisseur, responsables de traiter les incidents les plus critiques ou spécialisés. Ils interviennent lorsque les incidents nécessitent des compétences avancées, souvent en lien avec des équipes externes.
- Utilisateurs finaux : Les utilisateurs finaux jouent un rôle essentiel en signalant rapidement les incidents et en fournissant des informations détaillées pour faciliter le diagnostic. Leur implication aide à accélérer la détection des problèmes et à minimiser leur impact.
.png)
3.2 Coordination entre le service desk (support de proximité) et les autres équipes
Le service desk est au centre du processus de gestion des incidents.En tant que premier point de contact pour les utilisateurs (et parfois point de contact unique → Single Point Of Contact / SPOC), il est responsable d’accueillir les signalements, d’enregistrer les incidents dans le système de gestion, et de fournir un support de premier niveau.
- Enregistrement et suivi des incidents : Le service desk assure le suivi de chaque incident, réalise le premier diagnostic, met à jour les utilisateurs sur l’état de la résolution, et garantit que les informations sont bien documentées pour une traçabilité complète.
- Escalade : Lorsque les incidents ne peuvent pas être résolus au niveau 1, le service desk les transfère aux équipes de support de niveau supérieur. L’escalade est essentielle pour garantir une intervention rapide et appropriée en fonction de la gravité et de l’impact de l’incident.
- Retour d’information : Le service desk joue également un rôle crucial dans la communication avec les utilisateurs, en transmettant les mises à jour fournies par les équipes de support pour rassurer les utilisateurs et répondre à leurs questions.
Une collaboration étroite entre le service desk, les équipes de support, et les autres départements est nécessaire pour assurer une réponse cohérente et rapide aux incidents.
3.3 Collaboration avec les fournisseurs externes et parties prenantes
Dans les environnements IT actuels, de nombreux services et solutions sont externalisés, ce qui implique une coopération étroite avec les fournisseurs.
- Accords de Niveau de Service (SLA) : Les SLAs établissent des délais et des critères de qualité pour les interventions des fournisseurs externes. Ils définissent les attentes en matière de réponse, de résolution, et de communication pour les incidents affectant des services externalisés.
- Suivi et gestion des performances : Le gestionnaire d’incidents travaille en lien avec les fournisseurs pour s’assurer que les engagements des SLA sont respectés. Les fournisseurs sont souvent sollicités en cas d’incidents complexes ou nécessitant une expertise technique spécifique.
- Escalade et communication : En cas de non-respect des SLAs ou d'incidents majeurs, des processus d’escalade vers les responsables des fournisseurs peuvent être mis en place. Cette collaboration garantit une prise en charge rapide et un suivi rigoureux des incidents externalisés.
3.4 Importance de la communication
Une communication efficace est indispensable dans le déroulé du processus de gestion des incidents, tant pour les utilisateurs que pour les équipes internes.
- Communication avec les utilisateurs : Informer régulièrement les utilisateurs de l’état des incidents réduit l'incertitude et améliore la transparence. Cela peut inclure des notifications automatiques pour les mises à jour de statut, des estimations de temps de résolution, et des conseils temporaires pour contourner les problèmes.
- Communication inter-équipes : Une coordination fluide entre le service desk, les équipes de support, et les fournisseurs externes est cruciale pour éviter les doublons et s’assurer que chaque intervenant connaît son rôle et ses responsabilités.
- Documentation et post-incident : Une documentation claire permet de garder une trace de chaque étape et de préparer les rapports post-incident (ou post-mortem), essentiels pour analyser les causes et tirer des leçons pour prévenir de futurs incidents similaires.
4. Organisation et processus de gestion des incidents
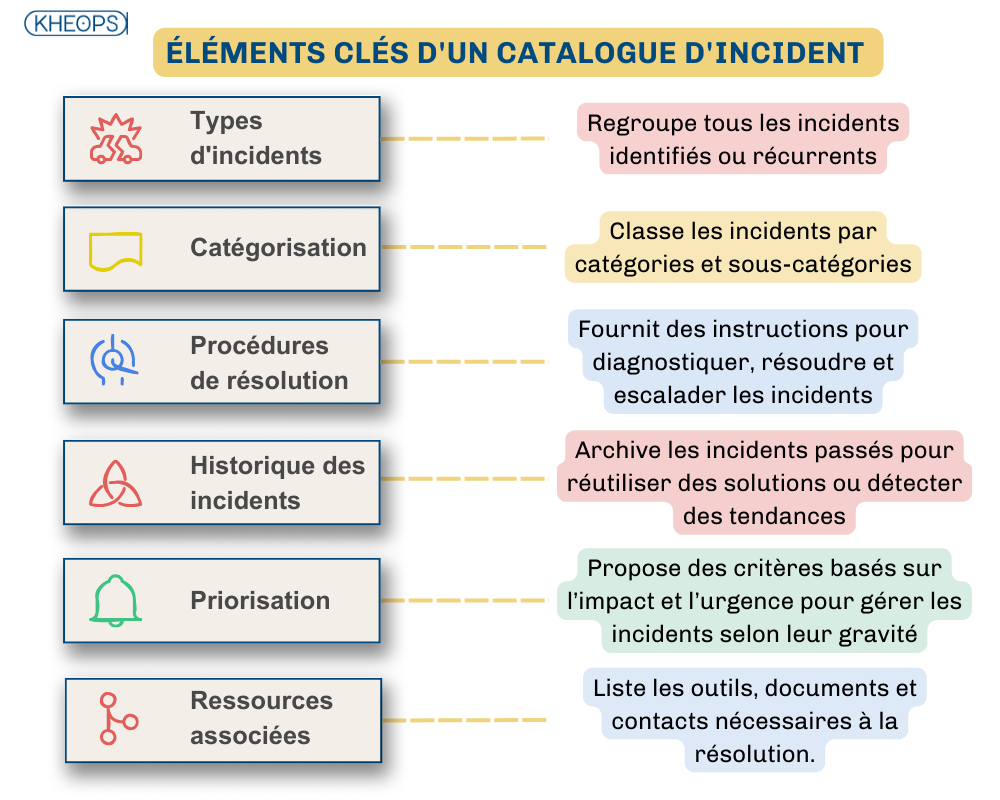
4.1 Catalogue d'incidents
Un catalogue d'incidents est un référentiel centralisé et structuré qui liste les types d'incidents fréquents rencontrés au sein d'une organisation.Il sert de base pour standardiser et accélérer la gestion des incidents, en fournissant des procédures et des informations claires sur la façon de traiter chaque type d'incident. L’objectif principal du catalogue d'incidents est de faciliter la résolution rapide des incidents en fournissant aux équipes IT des directives éprouvées et des modèles de réponse.
‼️ Attention ‼️
Nous évoquons ici le catalogue d’incident car il est répandu, mais il s’agit rarement d’une bonne pratique !
En terme de parcours utilisateur et d’efficience du processus, proposer un catalogue d’incident freine l’accessibilité et la simplicité.Vos utilisateurs catégorisent-ils convenablement les tickets ? Très rarement …
D’expérience, il est préférable de proposer l’ouverture d’un ticket d’incident à travers un formulaire unique. Ce ticket sera quoi qu’il arrive diagnostiqué au Support de Niveau 1, alors pourquoi complexifier ? (Les industriels y verraient un “Muda” : un gaspillage).
4.2 Priorisation des incidents : matrice impact-urgence et SLAs
La priorisation des incidents permet de traiter les problèmes en fonction de leur impact sur les activités métiers et de leur urgence. Cela permet d’allouer les ressources de manière optimale et de garantir que les incidents les plus critiques sont résolus en priorité.
Impact vs Urgence
- Impact : Mesure de l’effet négatif qu’un incident a sur l’activité métier. Plus l’incident perturbe des processus métiers clés (ex. interruption d’un ERP ou d’un système de production), plus son impact est élevé. Un incident affectant un petit groupe d’utilisateurs peut avoir un impact moindre, tandis qu'un incident touchant une fonction critique comme les RH/finances aura un impact majeur.
- Urgence : Mesure du temps sous lequel un incident doit être résolu pour éviter de compromettre davantage les activités. Un incident peut avoir un faible impact mais être très urgent, par exemple, un outil de collaboration temporairement inutilisable, ou au contraire, un incident majeur mais non urgent qui peut attendre quelques heures ou jours.
La matrice impact-urgence est utilisée pour déterminer la priorité d’un incident. Cette matrice croise ces deux dimensions pour évaluer la criticité d’un incident et définir l’ordre de traitement.
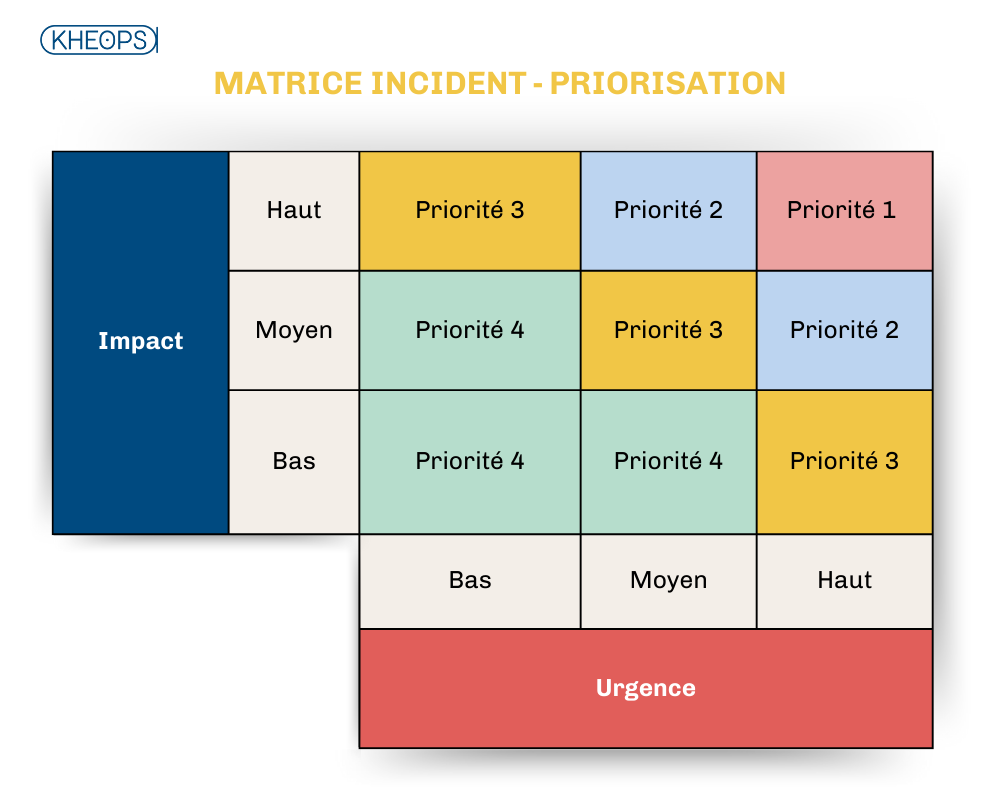
Accords de Niveau de Service (SLAs)
Les SLAs (Accords de Niveau de Service) sont des engagements formalisés sur les délais de réponse et de résolution des incidents. Chaque priorité d’incident est associée à des objectifs de temps pour la prise en charge et la résolution :

Ces SLAs permettent de structurer les attentes des utilisateurs et de garantir un service de qualité en cas d'incidents.
4.3 Cycle de vie d'un incident
Le cycle de vie d’un incident couvre toutes les étapes depuis son signalement jusqu’à sa résolution et clôture. Ainsi les différents statuts suivants permettent de suivre l’avancement de l’incident dans son cycle de vie :
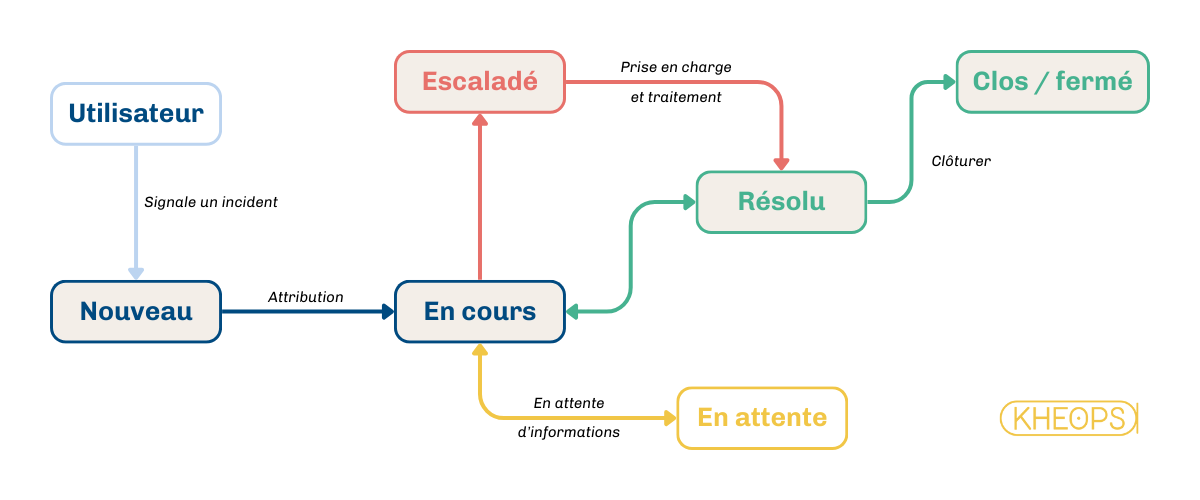
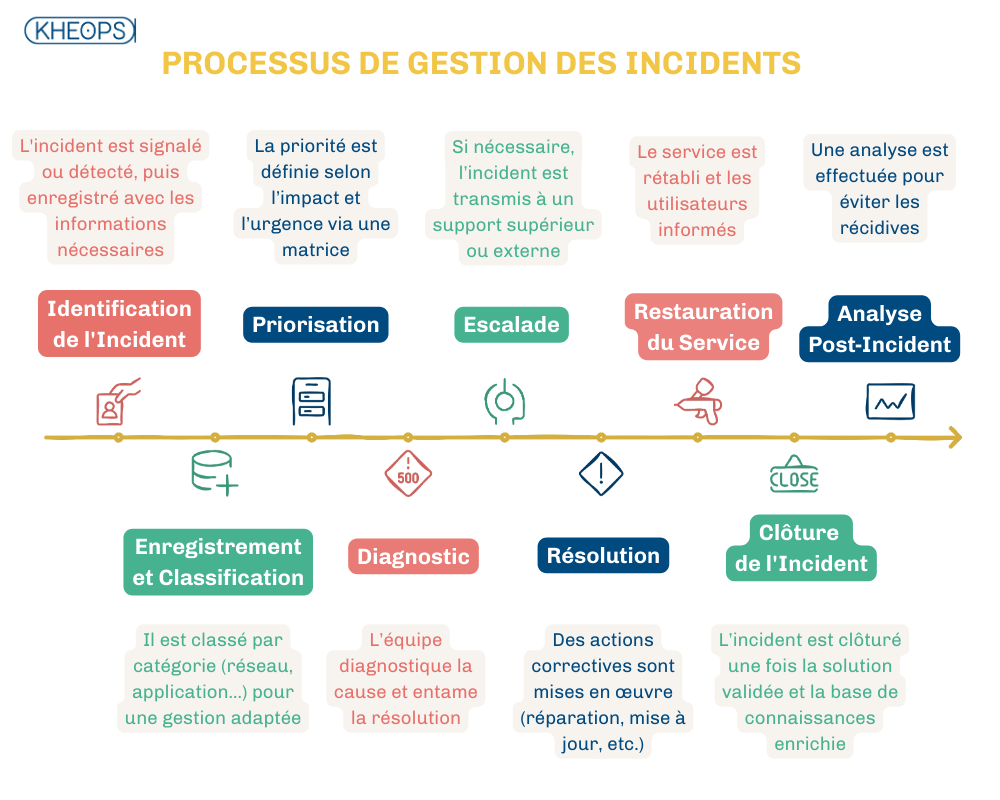
4.4 Étapes clés du processus de gestion des incidents
Le processus de gestion des incidents suit une série d'étapes structurées pour garantir une résolution rapide et efficace des incidents. Voici les étapes clés :
5. Gouvernance, outillage et indicateurs de suivi de la gestion des incidents
5.1 Outillage : outils de ticketing, monitoring, gestion des connaissances, CMDB
Les outils constituent le socle technique de la gestion des incidents. Chaque organisation doit se doter d'un ensemble d’outils adaptés pour maximiser l'efficacité des équipes IT et faciliter le suivi des incidents :
- Outils de ticketing : Centraux pour la gestion des incidents, le ticketing permet d'enregistrer, suivre et gérer les incidents tout au long de leur cycle de vie. Il permet d'attribuer un numéro d'incident unique, d'associer des informations clés (priorité, catégorie, description, etc.), et de suivre les actions pour résoudre l'incident. L'outil facilite également la communication entre les équipes de support et les utilisateurs.
- Outils de monitoring, supervision, observabilité : Les outils de monitoring surveillent en temps réel les systèmes, applications et réseaux pour détecter des anomalies ou des défaillances potentielles. Ils génèrent des alertes automatiques en cas de problème, permettant aux équipes IT d'intervenir rapidement, souvent avant même que l'incident ne soit signalé par l'utilisateur. Cela améliore la réactivité et réduit le temps de résolution.
- Gestion des connaissances (Knowledge Base) : Un référentiel centralisé de gestion des connaissances (base de données de solutions ou FAQ) permet aux équipes de support d’accéder rapidement à des informations sur les incidents précédents et leurs résolutions. Cela aide à résoudre les incidents plus rapidement en réutilisant des solutions éprouvées et à réduire la charge de travail en évitant des recherches répétitives.
- CMDB (Configuration Management Database) : La CMDB assure une vue centralisée de tous les actifs IT (matériel, logiciels, configurations réseau) et des relations entre eux, permettant de diagnostiquer plus précisément les incidents et d’évaluer les impacts potentiels.
5.2 KPIs clés pour le pilotage et suivi des activités
Les indicateurs de performance (KPIs) sont essentiels pour mesurer l’efficacité de la gestion des incidents et pour optimiser les processus. Ils permettent d'évaluer la performance des équipes, la qualité du service rendu aux utilisateurs et l'impact des incidents sur les activités de l'entreprise.
Voici quelques KPIs clés à suivre :
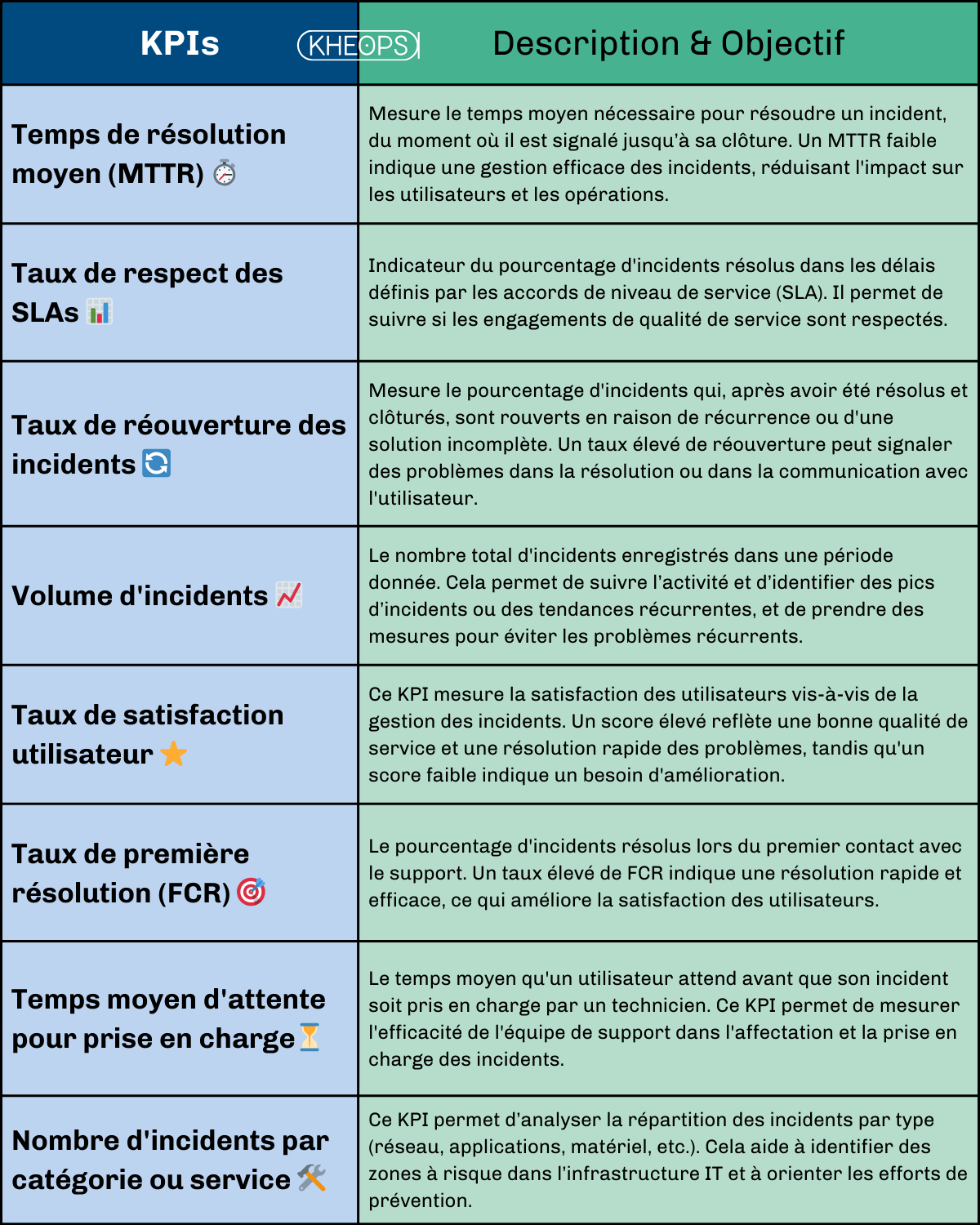
MTTR = (mean time to repair) et FCR = (first call resolution)
Ces KPIs permettent de suivre la performance de la gestion des incidents, d'identifier des axes d'amélioration, et de garantir une gestion optimale des incidents, tout en maintenant la satisfaction des utilisateurs et en limitant l'impact sur les activités de l'organisation.
5.3 Cadre de gouvernance : comités, réunions de suivi
Un cadre de gouvernance clair assure une supervision rigoureuse des processus de gestion des incidents. Cela inclut des comités de pilotage, des réunions de suivi régulières, et des rituels de performance pour évaluer les résultats, identifier les axes d’amélioration, et coordonner les actions. Une bonne gouvernance garantit également que la gestion des incidents s’inscrit dans une logique d'amélioration continue et de conformité avec les meilleures pratiques ITSM.
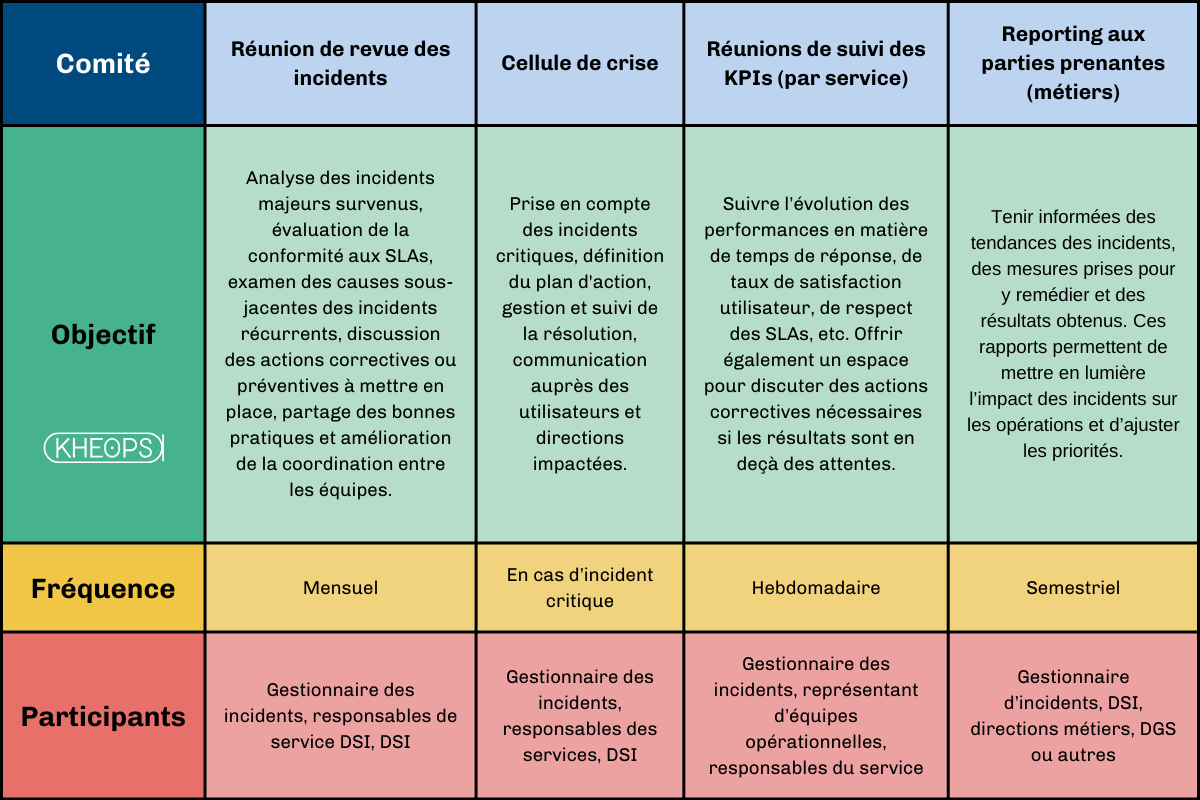
6. Amélioration continue et gestion proactive des incidents
6.1 Évaluation de la satisfaction des utilisateurs
L'évaluation régulière de la satisfaction des utilisateurs est essentielle pour mesurer l’efficacité du processus de gestion des incidents.Des questionnaires de satisfaction sont utilisés pour recueillir des avis sur la gestion des incidents, en particulier sur la rapidité, la qualité du support, et la résolution des problèmes. Ces retours permettent de mieux comprendre les attentes des utilisateurs, d'identifier les domaines d'amélioration et d’adapter les processus ou les formations nécessaires pour optimiser la réponse aux incidents.
6.2 Gestion proactive des incidents par la supervision
La supervision proactive est un processus clé permettant de détecter les signes précurseurs d’incidents avant qu'ils n'affectent les utilisateurs. En utilisant des outils de monitoring avancés qui surveillent en temps réel la performance des systèmes, les équipes IT peuvent intervenir rapidement dès qu’un dysfonctionnement est détecté. Cette approche permet de minimiser les interruptions et de maintenir une qualité de service élevée, renforçant ainsi la stabilité de l'infrastructure IT.
6.3 Automatisation et IA pour optimiser les processus
L'intégration de l'intelligence artificielle et de l'automatisation offre de nouvelles perspectives pour optimiser la gestion des incidents. L'IA peut anticiper les incidents en analysant des modèles de données, les logs et en détectant des anomalies, permettant une intervention avant même que les utilisateurs ne soient impactés.De plus, l'automatisation de certaines tâches répétitives, comme l’enregistrement ou la résolution d’incidents simples via des chatbots, libère du temps pour les équipes de support, leur permettant de se concentrer sur des problèmes plus complexes. Ces technologies améliorent la réactivité et la qualité du service.
6.4 Révision post-incident et analyse post-mortem
Les analyses post-mortem sont menées après des incidents critiques pour évaluer les causes profondes, les actions, et les leçons à en tirer. Ce processus de révision offre une compréhension approfondie des défaillances et permet de mettre en place des actions correctives pour prévenir des incidents similaires à l'avenir. Elles font partie du processus d'amélioration continue, visant à renforcer la résilience de l'infrastructure IT.
6.5 Introduction à la gestion des problèmes
La gestion des problèmes est étroitement liée à la gestion des incidents, mais avec un objectif différent : identifier et éliminer les causes racines des incidents récurrents. Tandis que la gestion des incidents se concentre sur la restauration rapide des services, la gestion des problèmes vise à apporter des solutions durables pour minimiser la probabilité de nouveaux incidents. Ce processus s’appuie sur une analyse systématique des incidents passés pour identifier les problématiques structurelles à corriger.
7. Conclusion : Enseignements clés et perspectives
En conclusion, la gestion des incidents est une composante principale et stratégique de l’ITSM qui contribue directement à la stabilité, la performance des services IT.En structurant rigoureusement le processus de gestion des incidents, les organisations peuvent minimiser les interruptions, optimiser l’efficacité de leurs équipes et améliorer l'expérience utilisateur. À long terme, la mise en place de processus de gestion proactive et de révision post-incident permet de renforcer la résilience de l’infrastructure IT.
L’extension vers la gestion des problèmes complète cet écosystème en apportant une dimension préventive essentielle pour une DSI mature et orientée vers l'excellence opérationnelle.
La gestion des incidents est un élément fondamental de l'ITSM, visant à assurer la continuité des services informatiques tout en minimisant l'impact des interruptions sur les activités de l'organisation. À travers l'évolution des pratiques et l'adoption de nouvelles technologies, nous recensons 5 éléments clés pour la mise en place d’une gestion des incidents performante :
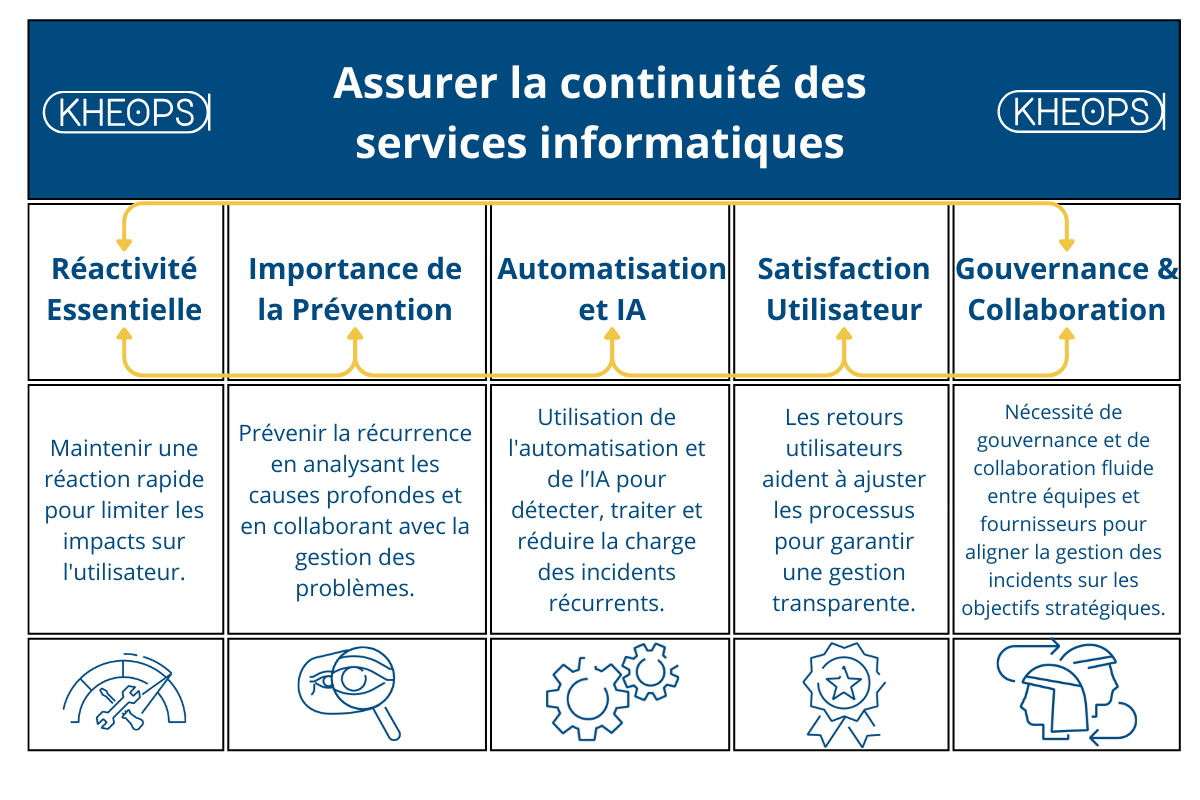
L'avenir de la gestion des incidents réside dans l’optimisation continue des processus par l’adoption de nouvelles technologies, telles que l'automatisation avancée, le machine learning, et la gestion prédictive des incidents. De plus, la montée en puissance des infrastructures Cloud et des services externalisés nécessitera une gestion encore plus proactive et intégrée des incidents, ainsi qu’une gestion collaborative avec les fournisseurs externes. La résilience et la sécurité des systèmes IT deviendront des priorités stratégiques, guidant les transformations à venir dans la gestion des incidents et des services.
8. Comment Kheops Conseil peut vous accompagner ?
La gestion efficace des incidents est un levier essentiel pour garantir la continuité des services IT et améliorer la satisfaction des utilisateurs. Chez Kheops Conseil, nous comprenons les défis uniques de chaque organisation et proposons un accompagnement sur mesure pour optimiser vos pratiques et vos outils ITSM.
Nos consultants, formés aux bonnes pratiques ITIL et experts en ITSM, interviennent pour vous aider à structurer et renforcer vos processus de gestion de services informatiques, en l’occurence la gestion des incidents. Voici un aperçu des sujets sur lesquels nous pouvons vous accompagner :
- Audit, amélioration des processus et construction de processus cibles : En réalisant un diagnostic approfondi de vos processus actuels, nous identifions les axes d’amélioration, concevons des workflows optimisés et définissons des processus cibles alignés avec vos objectifs stratégiques et les meilleures pratiques du marché.
- Gouvernance IT : Nous mettons en place des cadres de gouvernance clairs et efficaces pour garantir une gestion cohérente et durable des incidents.
- Choix d’un outil ITSM adapté et déploiement de l’outil ITSM : Nous analysons vos besoins spécifiques pour vous guider dans la sélection et l’intégration de la solution ITSM la plus pertinente pour votre entreprise. Nous vous accompagnons dans le déploiement de cet outil avec une approche garantissant une transition fluide et une prise en main efficace de l'outil par vos équipes.
- Formation et sensibilisation autour des pratiques ITIL/ITSM : Nous proposons des programmes de formation sur mesure pour vos équipes afin de renforcer leurs compétences en ITSM et les sensibiliser aux bonnes pratiques ITIL. Nos formations permettront à vos collaborateurs d’acquérir une maîtrise des processus et outils nécessaires pour une gestion des incidents optimale et efficace.
En fonction de vos besoins spécifiques, d’autres services peuvent être envisagés pour répondre aux défis uniques de votre organisation. Nous adaptons notre accompagnement pour vous aider à maximiser l'efficacité et la résilience de votre gestion des incidents, en lien avec vos priorités et vos enjeux business.
Avec Kheops, vous bénéficiez d’un accompagnement de bout en bout, axé sur la performance, la résilience et l’excellence opérationnelle. Contactez-nous pour en savoir plus et rejoignez les entreprises qui nous font confiance pour transformer leur gestion des incidents en un avantage stratégique durable.
Abonnez-vous au Papyrus
Chaque édition aborde un sujet précis : pilotage de la DSI, urbanisation, portefeuille projets, modèles opérationnels, rôle du DSI…


